A short report on Bittensor and AI
What in the world is a Bittensor and why should anyone care?


What have I gotten myself into?
If you’re reading this, you’re about to learn.
What’s up friends, it’s been a while. I hope all of you have been doing well and are hopefully enjoying some of the more recent positive price action across crypto. For my big return, I’ve decided to work through a more formal report on Bittensor in the context of the existing AI ecosystem. I’m not an expert on crypto, so I’m sure you can assume that I’m far less versed on AI. However, I actually spend a lot of my free time outside of crypto working on AI research and have been familiarizing myself with most of the important updates, advancements and pieces of existing infrastructure in the last 3-4 months, if not longer.
Despite some poorly worded and less than analytical tweets, I’m here to set the record straight. After reading all of this, you’ll know far more about Bittensor than you set out to, along with my thoughts on it, both good and bad. I know it’s a bit of a long report, I didn’t intend for that but a lot of this is because of screenshots and graphics. Please don’t feed this into ChatGPT to get a summary, I put time into these and you won’t get the whole story that way.
Disclaimers: I do not own any TAO and was not financially incentivized to write this. My views are my own and do not represent my employer, TCG Crypto. None of the information discussed herein is intended to be, or should be construed as financial advice, or an offer to sell or a solicitation of an offer to buy an interest in any security. The information set forth herein has been obtained or derived from sources believed by the author to be reliable and has been provided solely for informational purposes. Nevertheless, the author does not make any representation or warranty, express or implied, as to the information’s accuracy or completeness.

As I was in the process of writing this report, a dear friend of mine (who happens to be a beloved Crypto Twitter account, man oh man) messaged me and said that “AI + Crypto = future of finance” - as you read through this, try and keep that in the back of your mind.

Is AI the last piece of the puzzle to unleash cryptographic technology to the world, or is it just a small step towards achieving our goals? I won’t provide you with the answer, it’s on you to seek it out. Just some food for thought.
A little bit of background info
In their own words, Bittensor is essentially a language for writing numerous decentralized commodity markets, or ‘subnetworks’ situated under a unified token system with a goal of directing digital market power to society’s most important digital commodity, artificial intelligence.
Bittensor’s mission is to build a decentralized network capable of competing with models previously “only within the reach of immense supercorps like OpenAI” through its unique incentive mechanisms and an advanced subnetwork architecture. It’s best to imagine Bittensor as an entire system of interoperating parts, a machine built with the help of blockchains to better facilitate the movement of AI capabilities on-chain.
There are two key players that manage the Bittensor network, these being miners and validators. Miners are individuals who submit pre-trained models to the network in exchange for their share of rewards. Validators are the ones that confirm the validity and accuracy of these models’ outputs, selecting the most accurate ones to return to a user. An example of this might be a Bittensor user requesting an AI chatbot to answer a simple question involving derivatives or a historical fact, with this query being answered across however many nodes are currently running within the Bittensor network.
A simple explanation of a user interaction from start to finish with the Bittensor network is as follows: user sends query to a validator(s), validator(s) propagate this to miners whose outputs are then ranked by validators before the highest ranked outputs are sent back to the user.
This is all pretty straightforward.
By incentivizing models that routinely provide the best outputs, Bittensor creates a positive feedback loop in which miners compete amongst themselves to introduce more finely-tuned, accurate and performant models to grab a larger share of $TAO and facilitate a more positive user experience.
To become a validator, users must rank within the top 64 holders of TAO and have registered a UID on any of Bittensor’s subnetworks, the self-contained economic markets providing access to various forms of artificial intelligence. For example, subnet 1 focuses on token prediction via text prompts and subnet 5 is geared towards image generation. Both of these subnets might use different models, as their tasks are starkly different and may require more or less parameters, higher or lower accuracy on average and other domain-specific capabilities.
Another key aspect of Bittensor’s architecture is Yuma Consensus mechanism, comparable to a CPU that distributes Bittensor’s available resources across the entire network of subnetworks. Yuma has been described as a hybrid of PoW and PoS, with the added capability of transferring and facilitating (loosely defined) intelligence off-chain. While Yuma underpins most of Bittensor’s network, though subnetworks can opt in or out of relying on Yuma Consensus depending on their subnetwork’s chosen functionality. Details are murky and there are a variety of subnetworks with corresponding Githubs, so it’s fine to just understand the top-down approach of Yuma Consensus if you want only a general understanding.

But what about the models?
Contrary to popular belief, Bittensor does not train their models. This is an extremely expensive process, something that only larger AI labs or research organizations can afford, a process that can take a very long time. I’ve tried to get an absolute “yes” or “no” on the inclusion of training within Bittensor, but my only findings aren’t conclusive, which is still fine.

Decentralized training mechanism is a bit of a mouthful, but it’s actually not that hard to understand. Bittensor validators are tasked to “play a continuous game of evaluating the models produced by the miners on the Falcon Refined Web 6T token unlabelled dataset” in order to score each miner based on two criteria, timestamp and loss against other models. Loss functions are a machine learning term used to describe the difference between predicted and actual values in some type of simulation, with this being representative of the amount of error or inaccuracy of given input data and a model’s output.

And on the topic of loss functions, here’s the most recent performance of sn9 (pertaining subnetwork) that I grabbed from Discord yesterday, keeping in mind that lowest loss doesn’t necessarily mean average loss:

“Oh no, if Bittensor doesn’t train the models itself, can it do anything at all?!”
Slow your roll, this isn’t a deal breaker. In fact, there are three crucial stages in the “creation” of a large language model (LLM), these being training, fine-tuning and in-context learning (with a little bit of inference thrown in).
Before we proceed with some basic definitions, here’s a tidbit from a Sequoia Capital report on LLMs from June 2023 describing their findings from a survey: “15% built custom language models from scratch or open source, often in addition to using LLM APIs. Custom model training increased meaningfully from a few months ago. This requires its own stack of compute, model hub, hosting, training frameworks, experiment tracking and more from beloved companies like Hugging Face, Replicate, Foundry, Tecton, Weights & Biases, PyTorch, Scale, and more.”
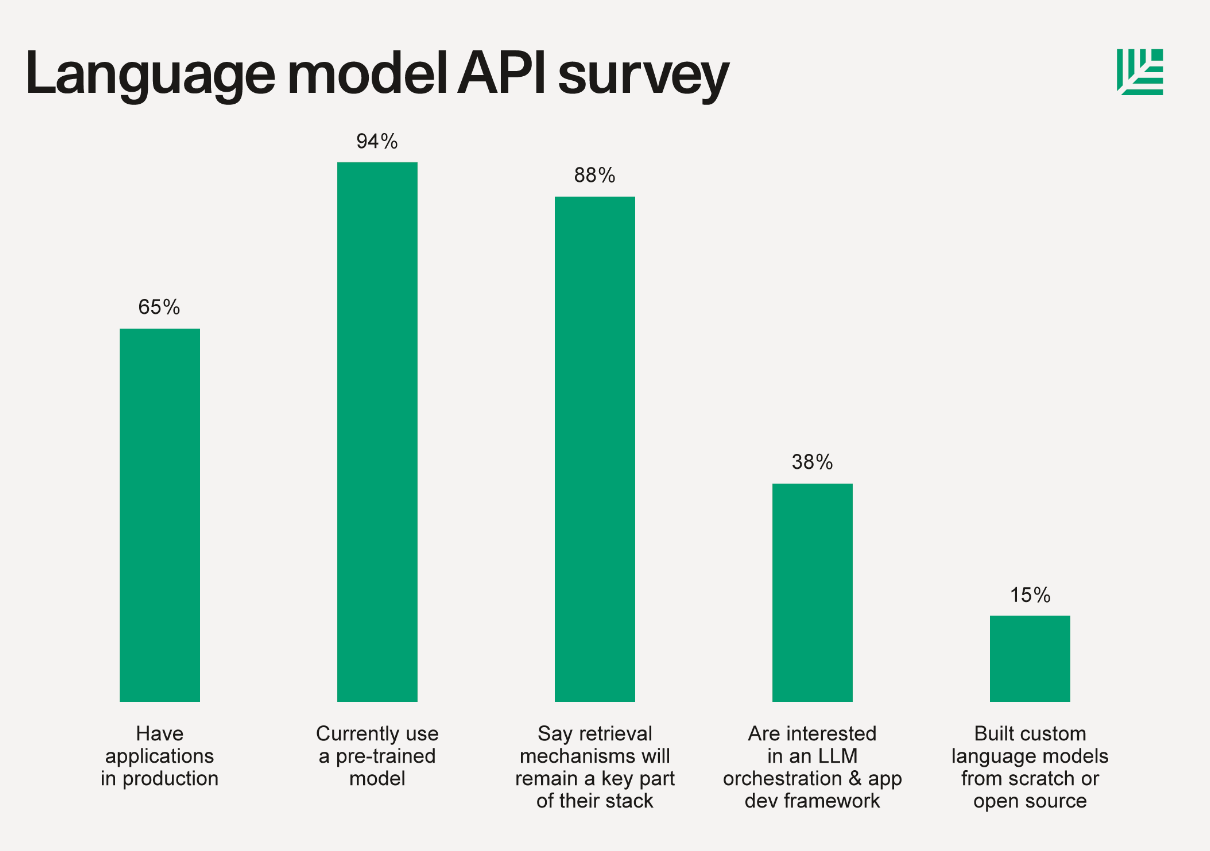
Building a model from the ground up is a difficult task, something that 85% of surveyed founders and teams did not wish to engage in. The process of self-hosting (Small side note, Bittensor actually fixes this), tracking results, creating or importing complex training playgrounds and the variety of other tasks is just too much work when most startups and solo developers only wish to utilize an LLM within an external application or software-based service. For 99% of those in the artificial intelligence industry, it’s not feasible to go out and create something comparable to GPT-4 or Llama 2.
This is why platforms like Hugging Face are so popular, as you can navigate to their site and download a model that’s already been trained, a process that’s very familiar and common to those in the AI industry.
Fine-tuning is more difficult, but suitable for those looking to offer an LLM-based app or service with a specific niche field or something similar. This could be a legal services startup developing a chatbot whose model was fine tuned on a variety of lawyer-specific data and examples or a biotech startup working on a model who has been fine-tuned specifically on whatever biotech relevant information there might be (just throwing out some examples here lol).

Regardless of the purpose, fine-tuning is meant to further drill personality or expertise into your model, making it more suitable and accurate at its tasks. And while it’s undeniably useful and more customizable, everyone agrees it’s difficult, even a16z:

Even though Bittensor doesn’t actually train the models, miners that submit their own models to the network claim to fine-tune them in some form, though this information isn’t available to the public (or is at least very difficult to verify, model weights and outputs aren’t my expertise and there isn’t a standardized way for me to check this without a lot of external work). Miners keep their model structures and capabilities a secret to protect their competitive advantage, though some are visible here and here on Weights & Biases, a platform for AI developer tooling.

Let’s give an easy example: if you were in a competition with a $1 million reward in which everyone was competing to see who had the best performant LLM, would you divulge that you’re using GPT-4 if all of your competitors were unknowingly using GPT-2? While it’s more complicated than this poorly thought out example explains, the reality isn’t that different. Miners are rewarded based on how often their outputs are generally accurate, creating an advantage over miners with maybe less fine-tuned models or models that are just worse performing on average. There are a ton of different models that are available, so it’s not entirely sure what specifications any given top 3 models might be week-to-week on Bittensor.
I mentioned in-context learning earlier, and this is probably the last portion of non-Bittensor information I’ll cover, but in-context learning is a broadly defined process for steering a language model toward more desirable outputs. Inference is the process a model constantly undergoes when evaluating inputs, a result of its training that can affect the accuracy of an output token. While training is expensive, it’s only done until a model is ready to achieve whatever level of training the team has specified in their process of creating a model. Inference is always occurring, with a variety of additional services used to facilitate the process of inference.
Current state of Bittensor
Now that all of that’s out of the way, I’ll explore some of the specifics regarding Bittensor subnetwork performance, current capabilities and what they plan to become in the future. To be completely honest, it was tough finding quality write-ups on this topic. Luckily I was sent a few from Bittensor community members, but even then it was a lot of work to form an opinion. I lurked around in their Discord a little bit to sleuth for answers, in the process realizing I’d been a member for about a month but hadn’t checked any of the channels out (I never use Discord, more of a Telegram and Slack guy these days).
Anyways, I decided to see what Bittensor’s original vision might have been, finding the following in a previously linked report:

I’ll cover it in a few paragraphs from here, but the compoundable thesis doesn’t hold up. There’s been some research done on the topic, and the same report the prior screenshot came from defined Bittensor’s current network as a sparse mixture model, a concept that was explored in this 2017 research paper. The authors were able to stack layers of up to 137b parameters and achieve (at the time) solid results compared to existing technology. As far as 2023 goes, there’s a lot of high level research to sift through on Arxiv and it’s difficult to replicate research results in the real world.
Moving on.
Bittensor has a lot of subnetworks, enough to where I felt it was necessary to give them an entire subsection in this report. Believe it or not, even though these are crucial to the utility of the network and underpin all of the technology, there isn’t a dedicated section on Bittensor’s website covering these and how they operate. I even asked around on Twitter a bit, but it seemed like the mysteries of subnetworks were only revealed to those who lounged around in Discord for hours and took it upon themselves to learn the operations of each. Regardless of the tall task presented to me, I set out to do some work.
Subnetwork 1 (often abbreviated as sn1) is the largest subnetwork of the Bittensor network, responsible for text generation services. Among the top ten validators of sn1 (I use same top 10 rankings for additional subnetworks), there are roughly 4 million TAO staked, followed by sn5 (responsible for image generation) which has about 3.85 million TAO staked. All of this data is available on TaoStats, by the way.
The multi-modality subnetwork (sn4) has about 3.4 million TAO staked, sn3 (data scraping) has around 3.4 million TAO staked and sn2 (multi-modality) has around 3.7 million TAO staked. Another subnetwork with more recent growth is sn11, responsible for text training with a similar amount of TAO staked as sn1.
That’s a lot of TAO.
In terms of minor and validator activity, sn1 is also the categorical leader here with over 40/128 active validators and 991/1024 active miners. Sn11 actually has the most miners of all subnetworks, with 2017/2048. The graph below depicts subnetwork registration costs over the past month and a half:
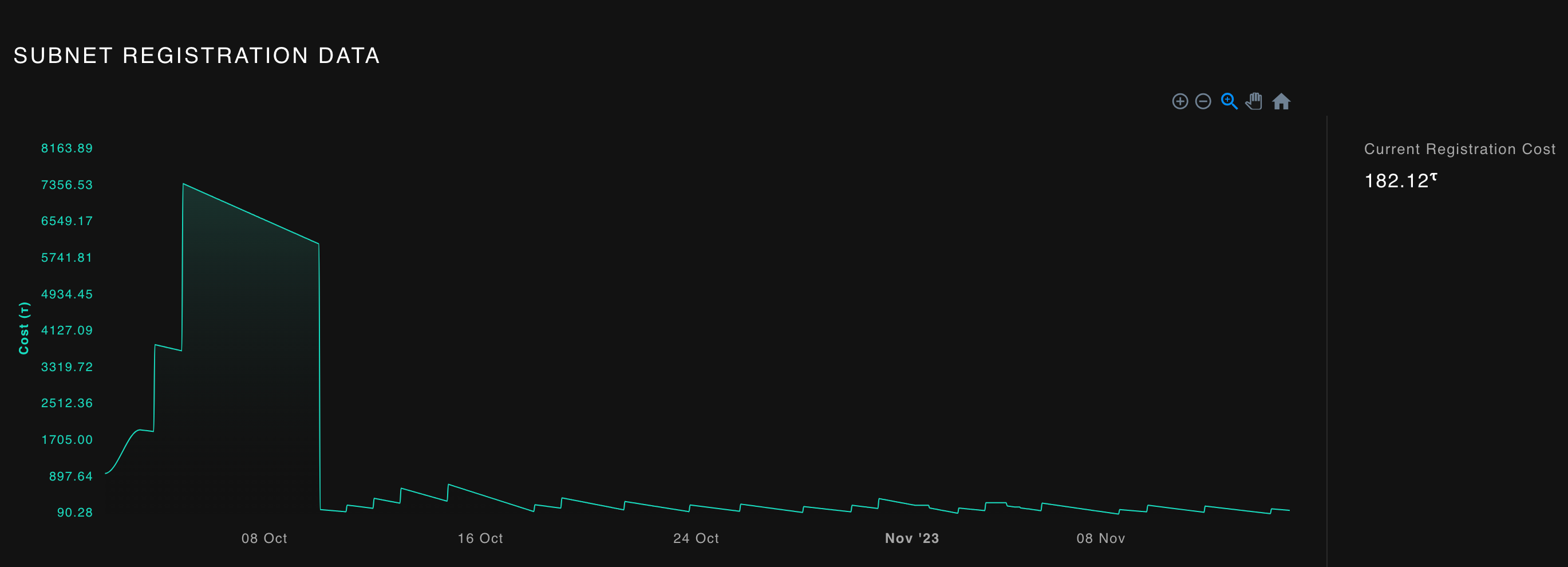
It currently costs 182.12 TAO to register a subnetwork, a number that’s come down significantly from a peak of over 7,800 TAO in October, though I’m not entirely sure that’s accurate. Regardless, with over 22 registered subnetworks and a growing spotlight on Bittensor, it’s likely we’ll see more subnetworks become registered in due time. It appears to take a while for some of these subnetworks to gain traction, due to reward share, distribution and utility in whichever step of inference they choose to target as a network.
As far as other subnetworks go, sn9 is a cool one that’s specifically geared towards training:

Here’s an explanation of one of Bittensor’s scraping subnets:

The subnetwork model is pretty unique and is often referred to as an example of another common technique in machine learning research known as a Mixture of Experts (MoE), a process where a model is split into parts and fed individual tokens rather than being assigned an entire task. This is interesting to me as Bittensor isn’t a unified model, but actually a network of models that are pinged for queries on a semi-random basis. An example of this process in action is BitAPI, a product built on top of sn1 that randomly samples through the top 10 miners for inbound user queries. While there might be dozens or even hundreds of miners in any given subnetwork, the top performing models are rewarded more frequently and disproportionately to ensure proper token outputs.
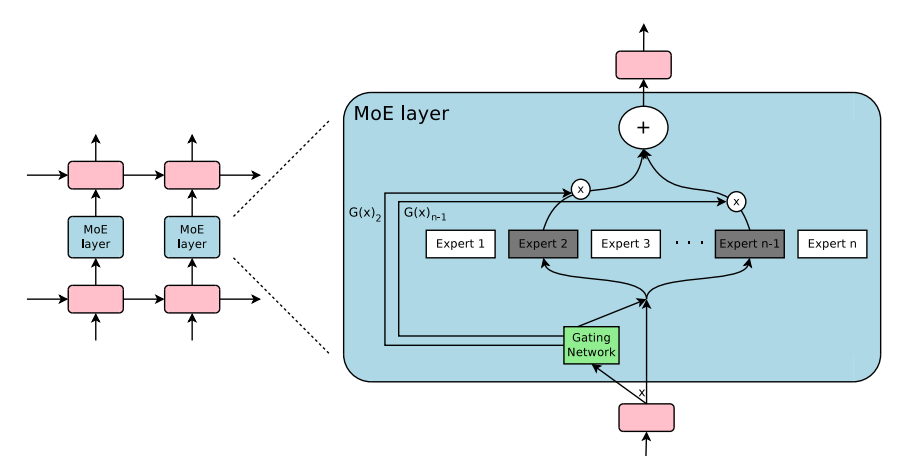
It’s not currently feasible to combine or compound many or even multiple models into one to increase or “stack” capabilities - it’s not how LLMs work. I’ve tried to reason with community members, but I think it’s important to note that as it stands, Bittensor is not an example of a unified collective of models, just a network of models of varying capabilities.
Some have compared Bittensor to an on-chain oracle with access to ML models, which is a pretty solid definition. Bittensor separates the core logic of the blockchain from the validation of subnetworks, running models off-chain in an effort to accommodate more data and higher compute costs for potentially stronger models. As you might recall, the only process done on-chain is inference. See the paragraph below for Bittensor’s explanation:

I think a lot of the community has gotten too wrapped up in trying to convince everyone that Bittensor is going to change the world when they’re actually just doing a pretty solid job of trying to change the way AI and crypto interact. It’s not likely they’ll be able to morph their entire network of miner-uploaded models to form one supremely intelligent super computer - that’s just not how machine learning works. Even the most performant and expensive models available (albeit in limited commercial form from research labs like OpenAI) are years away from achieving something definable as Artificial General Intelligence (AGI).
The definitions of AGI tend to differ as the machine learning community continues to iterate and expand on previously out of reach capabilities, but the basic idea is an AGI would be able to reason, think and learn exactly like a human. The core hang-up in this comes from the fact that scientists classify humans as beings with consciousness and free will, something that’s difficult to measure quantitatively in humans, let alone a robust system of neural networks.
As it stands, subnetworks are a unique way of breaking apart various tasks relevant to AI-based applications, and it’s up to the community and the team to attract builders who wish to utilize these core features of the Bittensor network.
It’s also worth adding here that Bittensor has been very productive in the machine learning world outside of crypto. Opentensor and Cerebras released the BTLM-3b-8k open-sourced LLM back in July of this year. Since then, BTLM has gone on to see over 16,000 download on Hugging Face with extremely positive reviews.
This account stated that BTLM-3b ranked highly in the same category as Mistral-7b and and MPT-30b as “best models per VRAM” thanks to BTLM’s lightweight architecture. Here’s a chart from the same tweet listing off models and their classifications of data accessibility, with BTLM-3b securing a nice scoring:
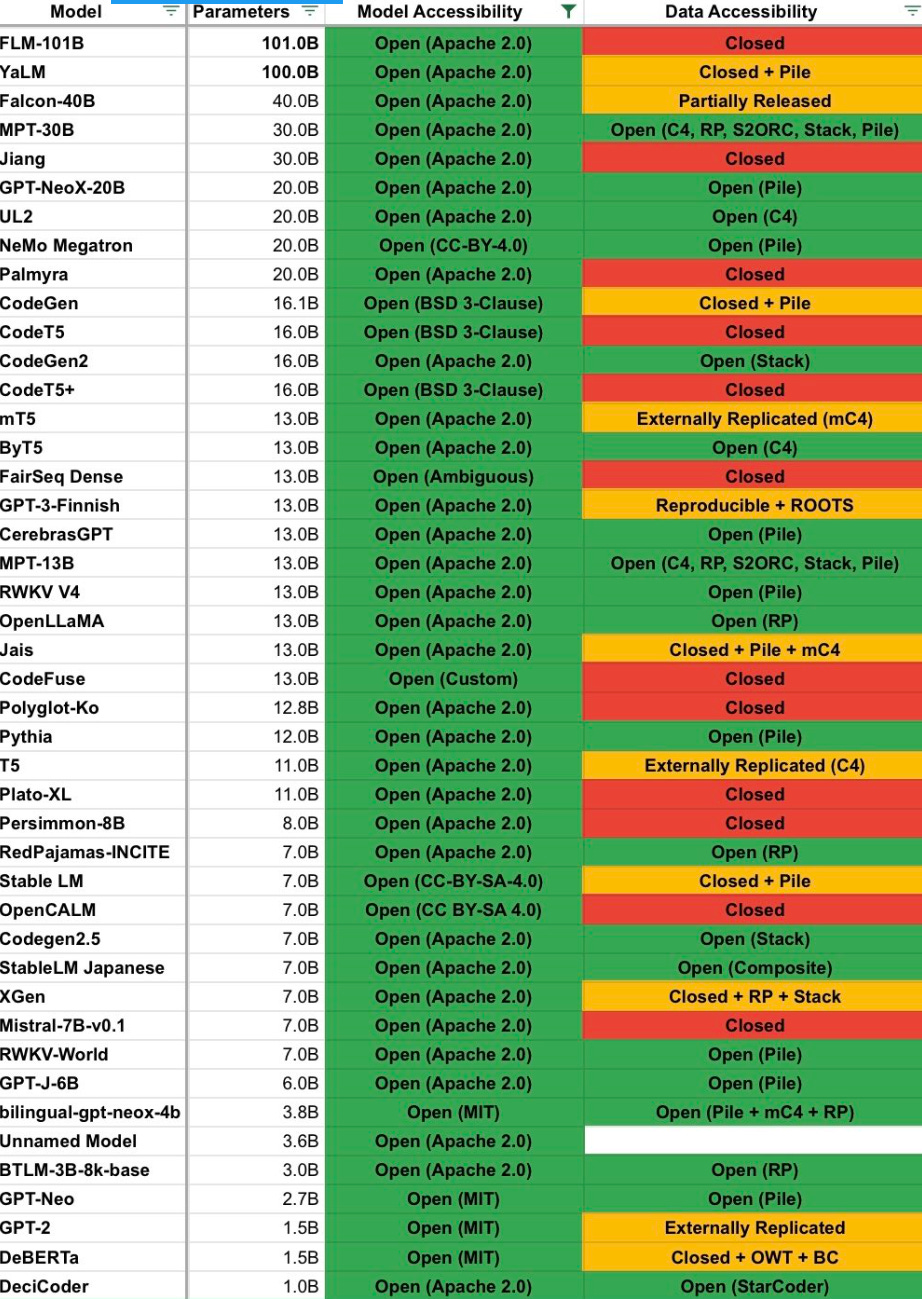
I know that I’d said on Twitter that Bittensor hadn’t done anything to accelerate AI research, so I figured it’s only right that I admit my wrongs here. Additionally, I’ve been told that BTLM-3b is utilized for validation in some instances as it’s cheap and fast to run on most hardware.
The utilities of TAO
I didn’t forget about the token, don’t worry.
Bittensor cites the inspiration of Bitcoin a lot, while also taking a page out of the OG’s textbook by incorporating a very similar tokenomics structure of a maximum 21 million TAO and a halving event every 10.5 million blocks. At the time of writing this, there are roughly 5.6 million TAO circulating, with a market cap of almost $800 million. The distribution of TAO can also be considered extremely fair, with this excellent Bittensor report stating that early supporters did not receive any tokens, though it’s difficult to verify whether this is or isn’t true, so we will trust our sources.
TAO is both a reward and access token to the Bittensor network, with TAO holders able to stake, participate in governance or use their TAO to access apps built on the Bittensor network. 1 TAO is minted every 12 seconds, with the newly minted token being distributed equally to both miners and validators for their work.
In my opinion, the tokenomics of TAO make it very easy (on paper) to envision a world where decreasing emissions via halvings lead to increased competition amongst miners, naturally resulting in higher quality models and a better user experience overall. However, there’s also the issue that less rewards does the opposite and doesn’t attract heightened competition, rather a stagnation in models deployed or the number of miners competing. This is more of a long term issue, though I figured I’d included it for some added context.
I could go on and on about token utility, price outlooks and growth drivers for TAO, but the previously mentioned report does a pretty good job of that. Most of Crypto Twitter has already established that there’s a very solid narrative behind Bittensor and TAO, nothing I add could fuel the fire any further at this point. From an outside perspective, I’d say these are fairly reasonable tokenomics and nothing is out of the ordinary, though I should mention it’s currently very difficult to purchase TAO as it isn’t widely available on most exchanges yet. This will probably change in 1-2 months, I’d be seriously surprised if Binance doesn’t jump on the TAO train soon.
Wrapping it up
I’ll let it be known that I am absolutely a fan of Bittensor and hope that they’re able to deliver on their bold mission. Just like the team said in their Bittensor Paradigm writing, Bitcoin and Ethereum were revolutionary as they democratized access to finance and made the idea of fully permissionless digital markets a reality. Bittensor is no different, with the goal of democratizing access to AI models within a vast network of intelligence. Despite my support, it’s clear they’re still far from where they want to be, but this can be said about most projects building in crypto. It’s a marathon, not a sprint.
If Bittensor wants to remain in the lead (as I believe they are) they need to continue pushing for friendly competition and innovation amongst miners while also expanding what’s possible in sparse mixture model architectures, MoE ideation and the concept of compounding intelligence in a decentralized way. Doing all of this on its own would be difficult enough, throwing cryptographic technologies into the equation makes it infinitely more challenging.
There’s 100% a long road ahead for Bittensor. Even though conversation surrounding TAO has picked up in recent weeks, I don’t think most of the crypto community is fully aware of how Bittensor works in its current form. There are obvious questions / problems that don’t have easy solutions, some of these being: a) whether or not it’s possible to achieve sufficient / high quality inference at scale, b) the problem of attracting users (with the equally as important task of attracting high quality apps that compete with the vast amount of non-crypto apps) and c) whether or not it makes sense to chase a goal of compounding LLMs.
Believe it or not, it’s actually been quite the challenge to champion a narrative of decentralized money on a large scale, though ETF rumors have made it a little easier, I’ll admit that.
Building a decentralized network of equally intelligent models that can iterate and learn from each other sounds too good to be true, and that’s partially because it is. It isn’t possible with current context windows and LLM restraints to have a model that self-improves over and over again until it reaches something comparable to AGI, even the best models available are still limited. Despite this, I think framing Bittensor as a decentralized LLM hosting platform with novel economic incentives and built-in composability is more than positive, it’s actually one of the coolest experiments in crypto right now.
Integrating economic incentives into an AI system has its challenges, as Bittensor has stated that they’ll adjust incentive mechanisms on a case-by-case basis if miners or validators attempt to game the system in any form. Here’s an example from June of this year which resulted in a 90% reduction in emissions:

This is totally expected in blockchain systems, so let’s not pretend Bitcoin or Ethereum have been perfect 100% of the time for their entire lifecycles.
The adoption of crypto has historically been a tough pill to swallow for outsiders, and AI is just as - if not more - controversial. Combining the two would give anyone a challenge in sustaining user growth and activity, it’s only natural that it will take some time. If Bittensor can eventually achieve its goals of compounding LLMs, maybe this could be something huge. Until then, I’m just going to continue observing activity, updated performance metrics and attempt to keep tabs on new projects and apps releasing within the ecosystem. That’s about it for me.
I hope this report was objective, unbiased and gave you a better understanding of Bittensor and how certain aspects of AI work. While I could’ve definitely written more, I decided it was best to release this as soon as possible to address the community and clear up some rumors. There is certainly a ton of information in the Bittensor Discord, enough that it would take me way too long to parse through all of it. Special thanks to everyone who helped me out in learning more about Bittensor, especially @jonitzler, @const_reborn and some others who will remain anonymous.
The Bittensor community was very harsh to me, but I don’t possess any ill will towards them. I think it would be beneficial for many community members to start contributing to the educational materials available on Bittensor, as there really aren’t that many. I was told that if I wanted to learn about the network and how complex it is, I’d need to spend weeks in the Discord to really immerse myself. Well, sorry to say it guys, but your Discord is pretty messy and not everyone has the time to hang out in a messaging server for 4 hours a day. Some of us have jobs.
Despite all of the hardships, I did my best and actually contributed some previously unknown information on Bittensor. There are maybe two really high quality reports out there cover this topic, yet a lot of valuable information is still missing even in these. If you want a project to do well and gain the support of outsiders, a good start is expanding the knowledge base and toning it down with the name calling, it really doesn’t establish much.

In the near future I plan to write another report covering additional projects building at the intersection of AI and crypto, so stay posted for that. Follow me on Twitter @knowerofmarkets and subscribe to the substack, it’s still free.
Thanks for reading and talk to you later!
Brilliant piece of work, thank you.